



In the MT-NLP Lab at LTRC, IIIT-H, work is undertaken in many different sub-areas of NLP including syntax and parsing, semantics and word sense disambiguation, discourse and tree banking, machine translation, creation of linguistics resources etc. Computational models are built inspired from linguistics, which are combined with machine learning techniques. For more information click
more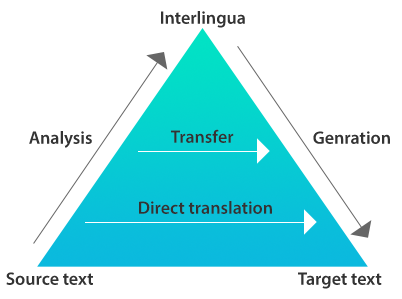
Vauquois Triangle

Anusaaraka is a machine translation tool being developed by the Chinmaya International Foundation (CIF), International Institute of Information Technology, Hyderabad (IIIT-H) and University of Hyderabad (Department of Sanskrit Studies). Fusion of traditional Indian shastras and advanced modern technologies is what Anusaaraka is all about. For more information click
moreThe objective of Speech and Vision Lab is to conduct goal oriented basic research, and thus we address fundamental issues involved in building robust speech-to-text systems, natural sounding text-to-speech systems, spoken/audio information retrieval and biometrics using speech and video. For more information click
more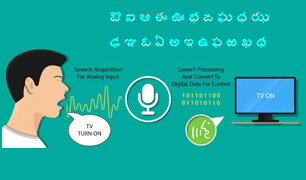

Search and Information Retrieval and Extraction Lab focuses on solving research problems in the areas of Information Retrieval (IR), Extraction (IE) and Access (IA). For more information click
more